Streaming thinking paradigm
Reasoning is synchronized with arriving text instead of being deferred until the full context is complete.
ICLR 2026 · Project Page
A streaming reasoning framework that aligns reading and thinking, enabling large language models to start reasoning before the full input has arrived.
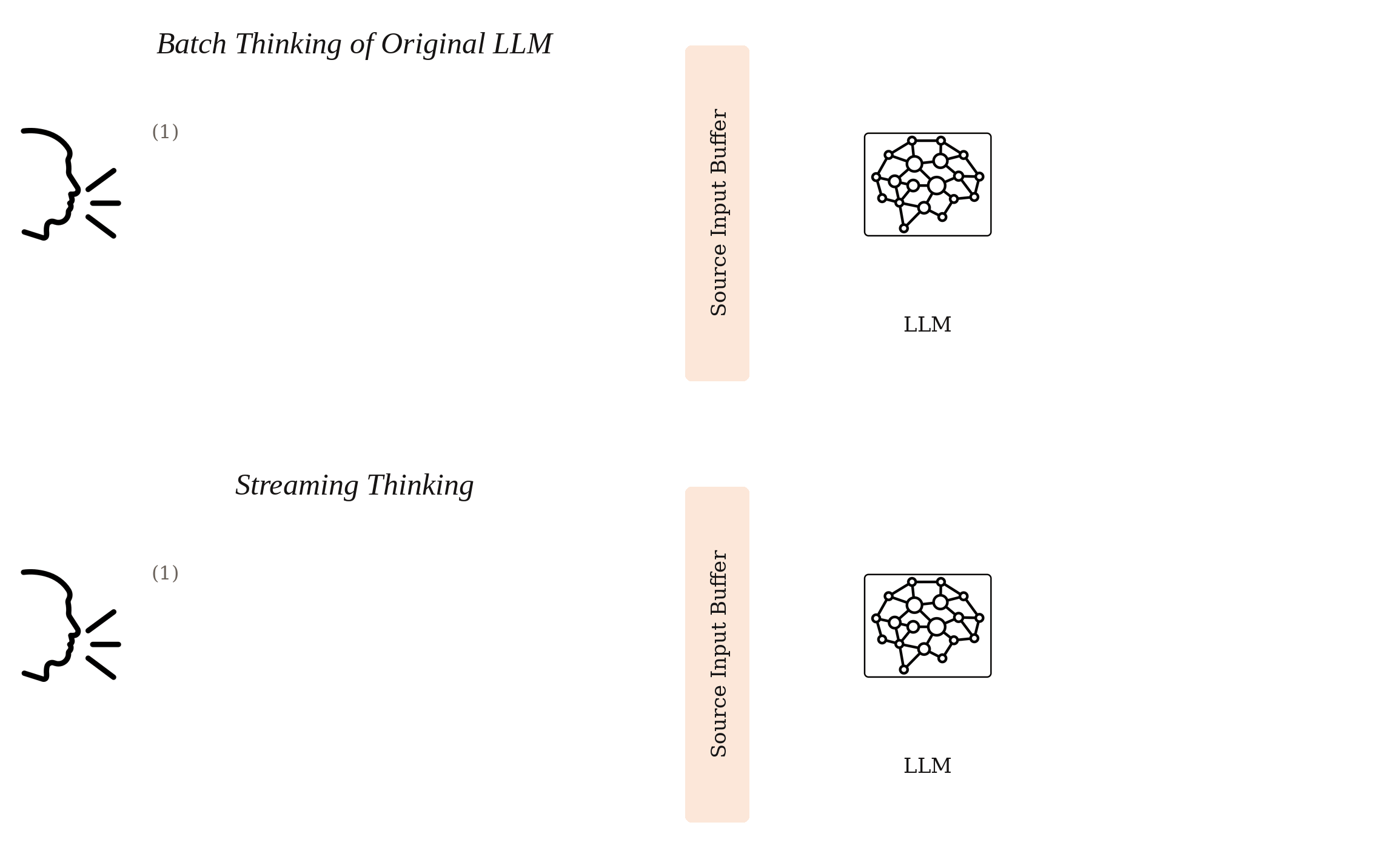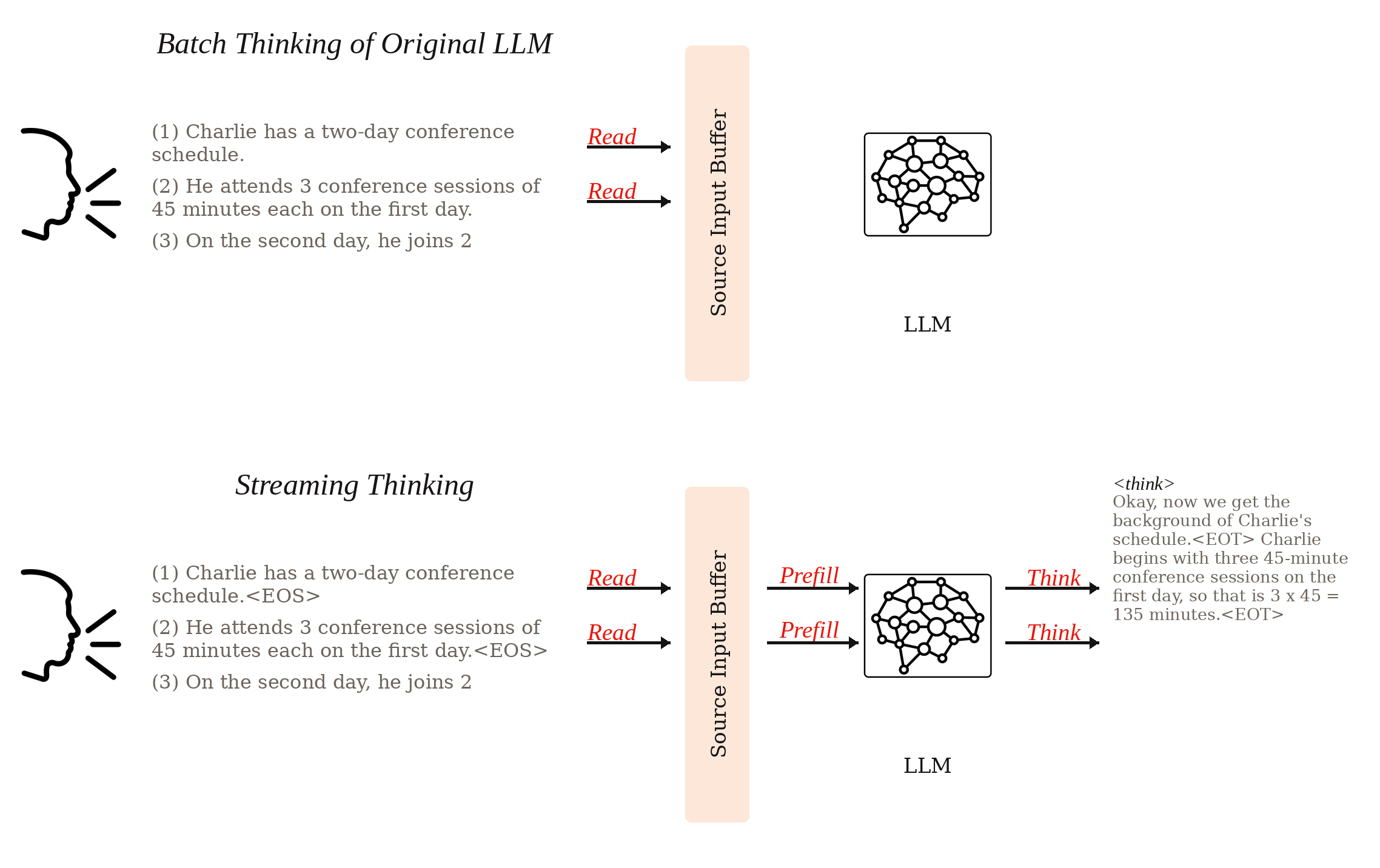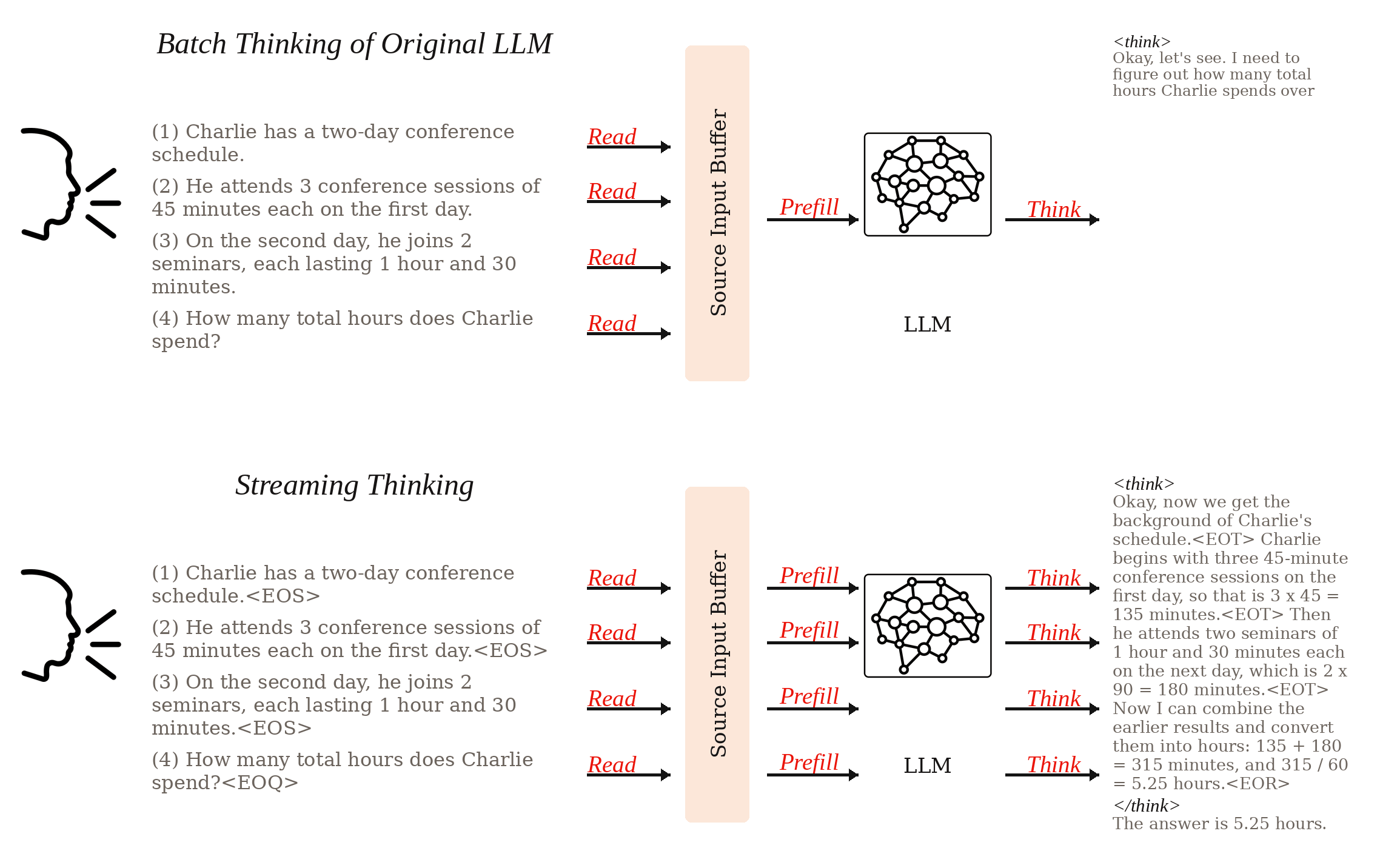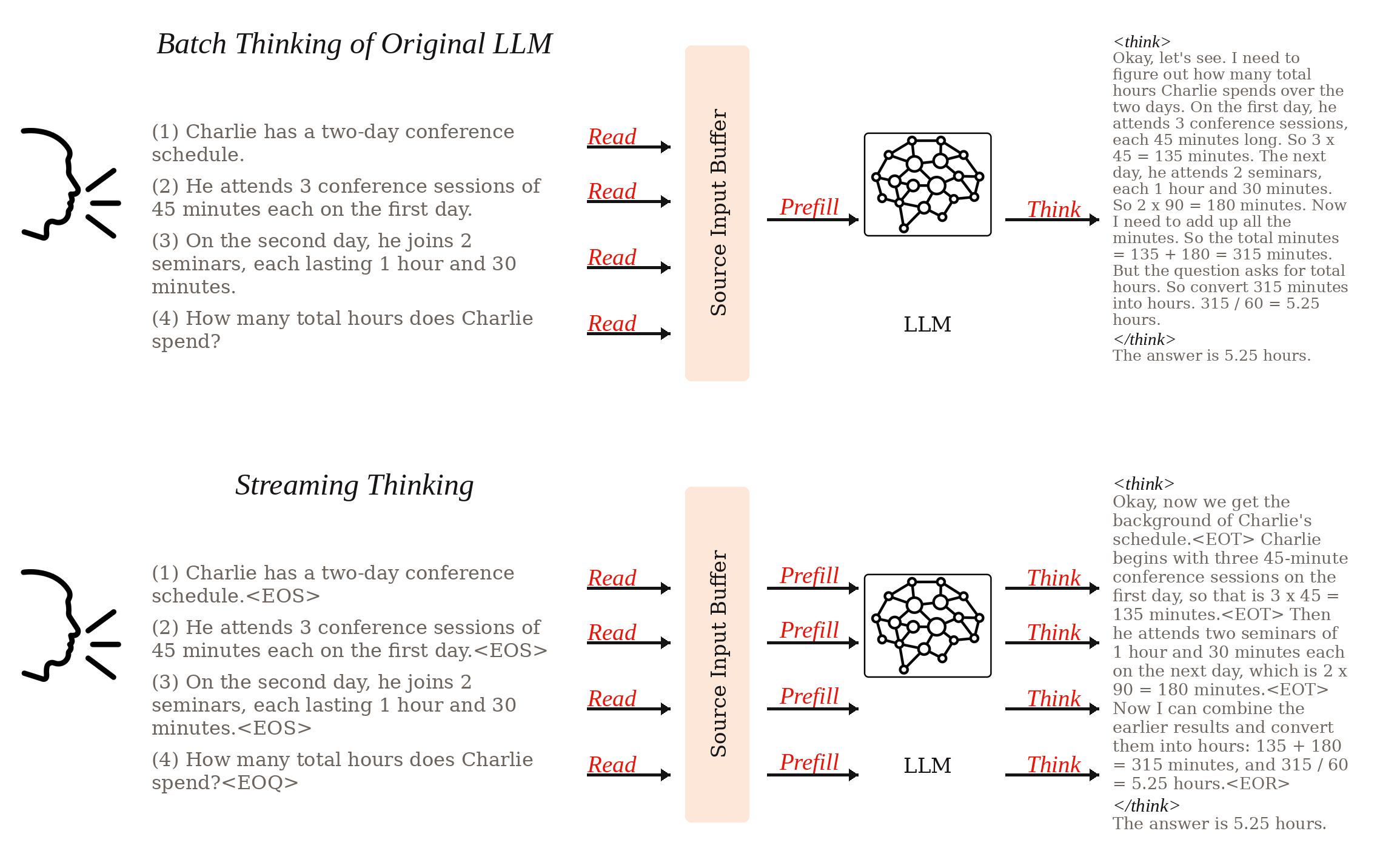
Large language models have become strong chain-of-thought reasoners, but standard inference still assumes a batch setting: the model waits until the entire input is available before starting to think. StreamingThinker introduces a streaming thinking paradigm in which reasoning follows the order of incoming evidence and can deepen once the full input has been observed. The framework combines streaming CoT generation, streaming-constrained training, and streaming parallel inference so that reading and reasoning can proceed concurrently while preserving order alignment. On the Qwen3 model family, the paper reports reasoning quality comparable to batch thinking together with substantial latency gains: roughly 80% less waiting before reasoning begins and more than 60% lower time-level latency for the final answer across math, logical reasoning, and context-based QA tasks.
Reasoning is synchronized with arriving text instead of being deferred until the full context is complete.
Streaming CoT supervision, streaming-constrained training, and parallel inference work together as a single stack.
The framework is designed to keep reasoning performance close to batch thinking while changing when reasoning happens.
The paper reports around 80% less waiting before reasoning onset and more than 60% lower final-answer latency.
01
StreamingThinker constructs supervision that follows sentence-level boundaries. The model learns to summarize key information, explain ambiguities, extend implications, and skip unnecessary local reasoning when the current stream segment is not useful.
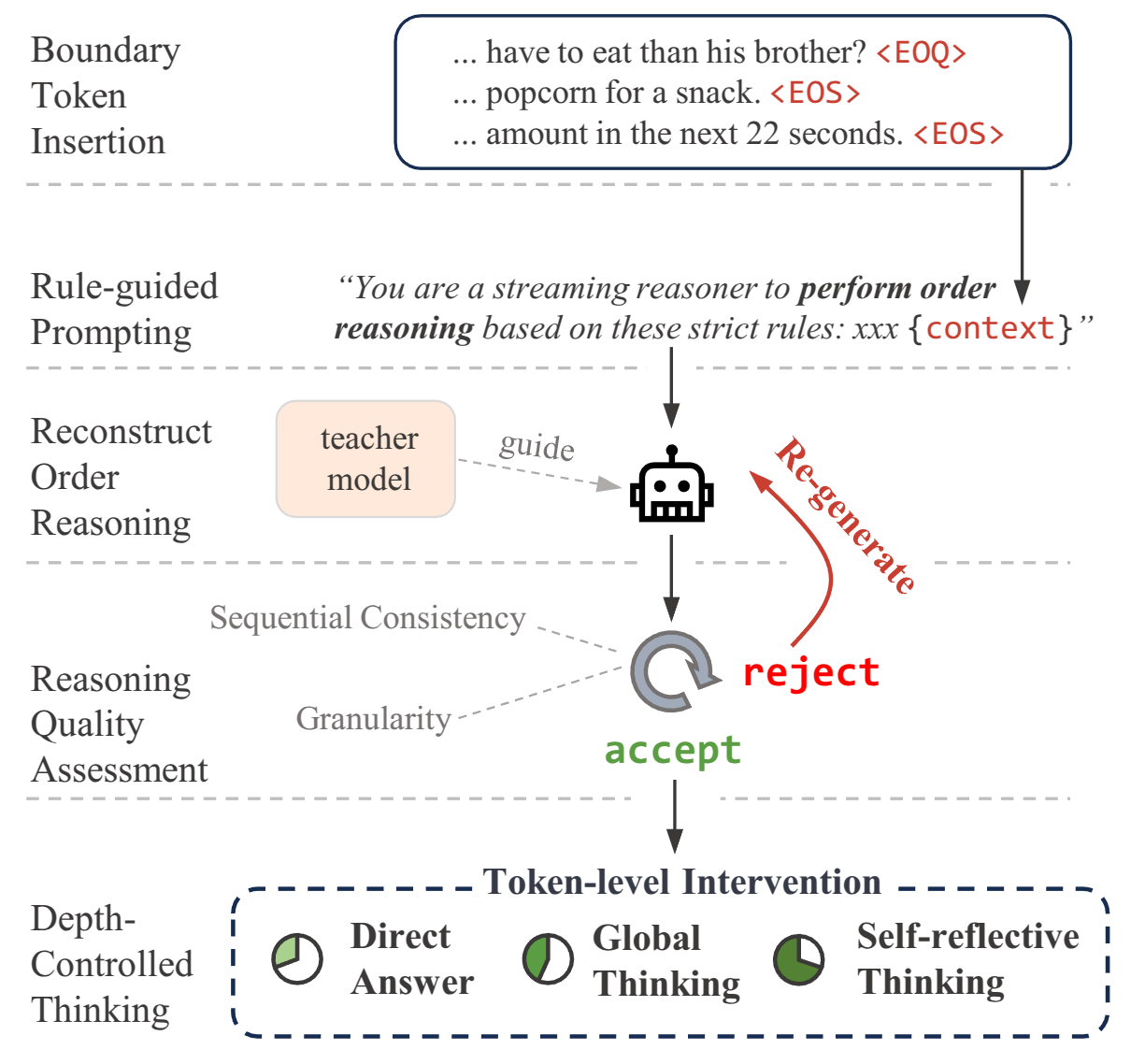
02
Training enforces order-preserving reasoning with streaming attention masks and decoupled position encoding. This keeps each reasoning step tied to the evidence already seen and avoids positional contention between source tokens and reasoning tokens.
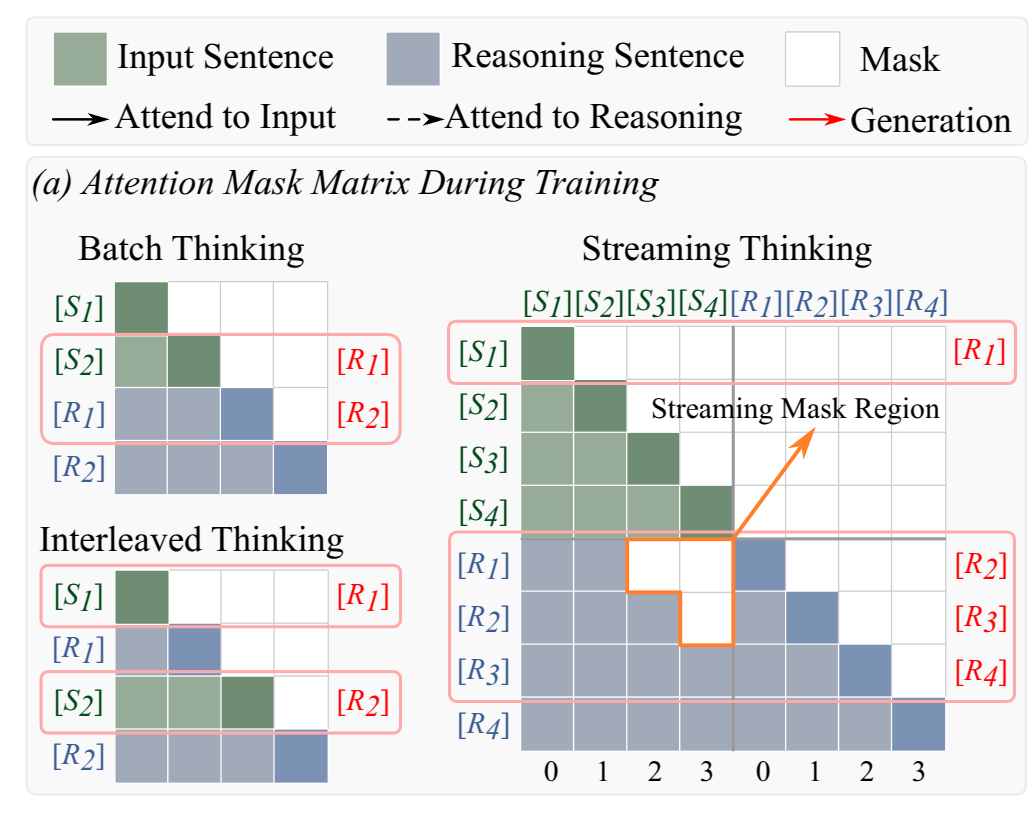
03
At inference time, separate KV caches are maintained for source-side reading and target-side reasoning. This decoupling enables true concurrency: the model can continue ingesting new input while generating reasoning tokens instead of alternating between the two in a fully serial loop.
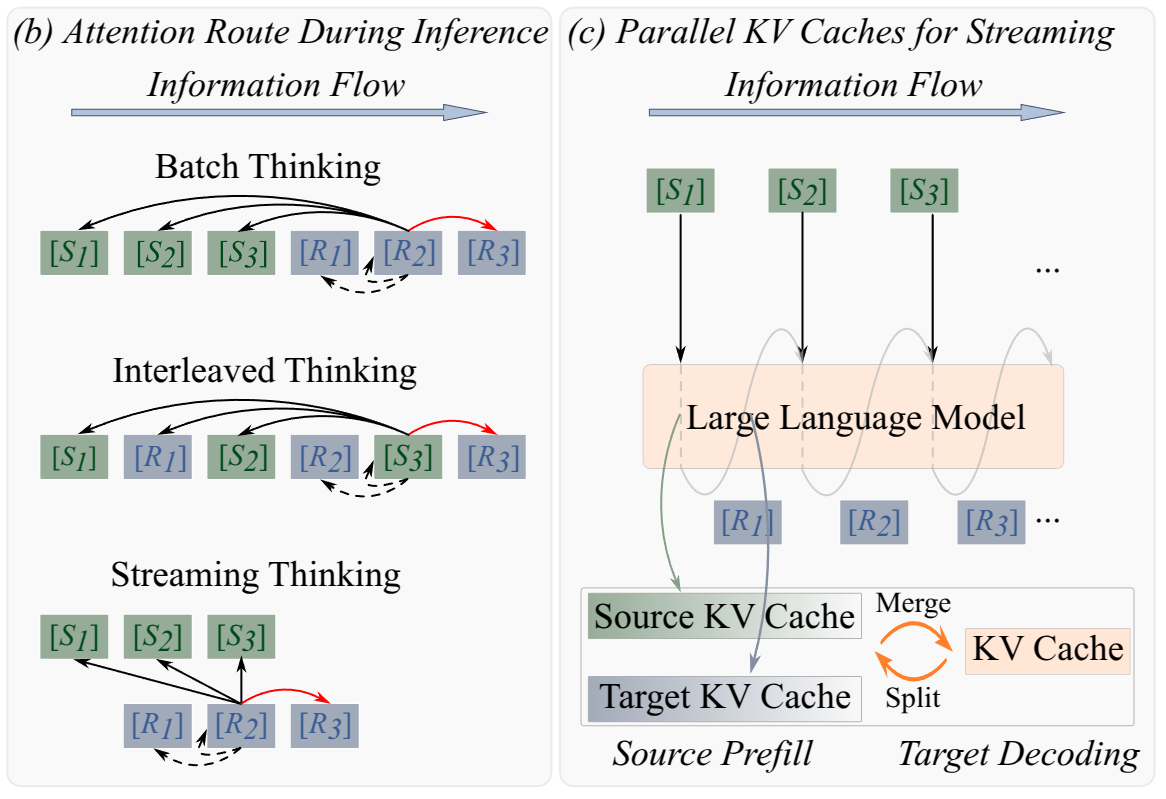
less token waiting before reasoning begins
lower time-level latency for the final answer
validated across math, logic, and context-based QA
reasoning performance relative to batch thinking
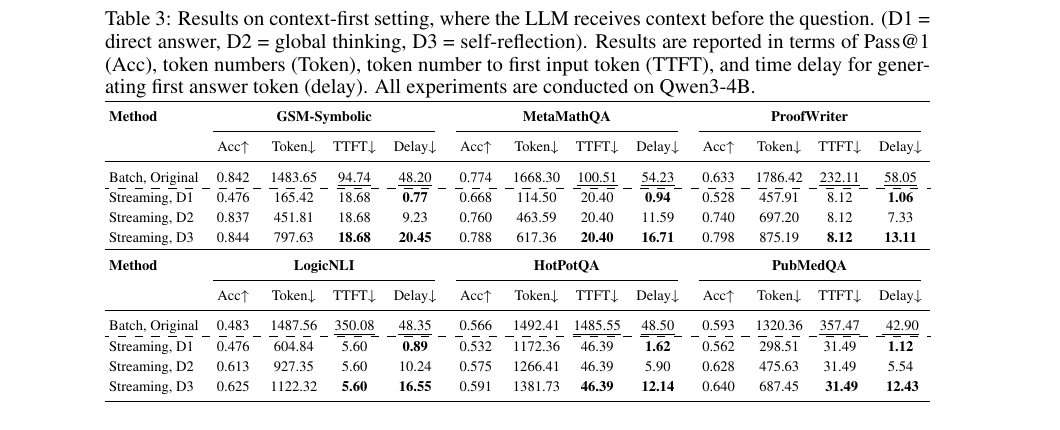
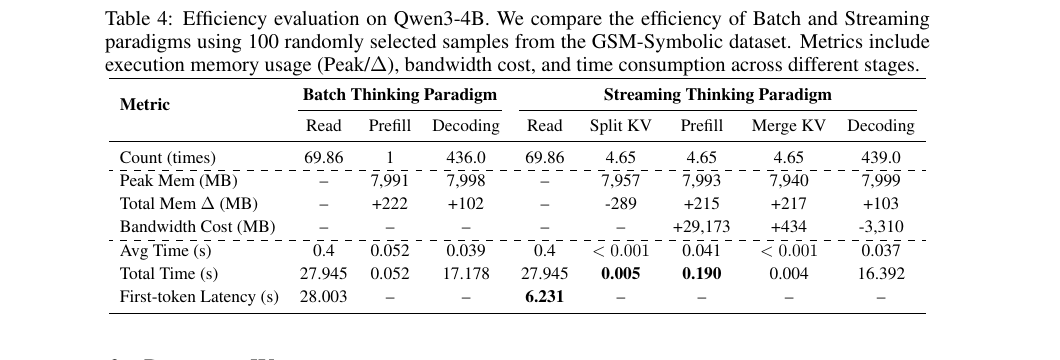
Below are direct screenshots from the paper for the three most relevant streaming result tables: real streaming evaluation, context-first streaming evaluation, and efficiency breakdown.
The main streaming comparison: batch thinking, naive interleaving, and parallel StreamingThinker.
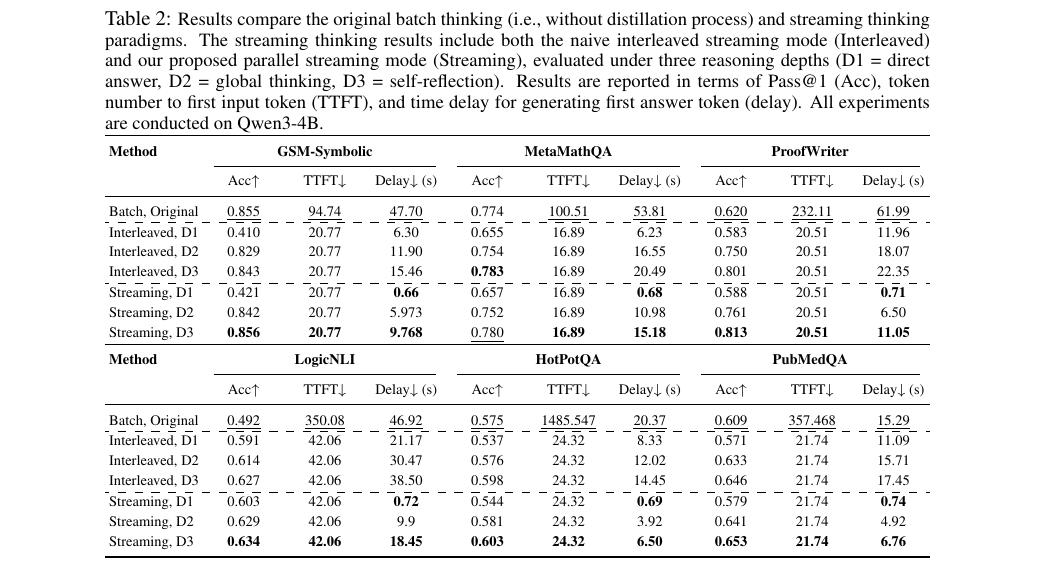
The context-first order is harder because the question arrives later. The paper reports that the model still preserves strong early-response behavior in this setting.
The efficiency breakdown shows where the latency reduction comes from in the parallel streaming pipeline.
@misc{https://doi.org/10.48550/arxiv.2510.17238,
doi = {10.48550/ARXIV.2510.17238},
url = {https://arxiv.org/abs/2510.17238},
author = {Tong, Junlong and Fan, Yingqi and Zhao, Anhao and Ma, Yunpu and Shen, Xiaoyu},
title = {StreamingThinker: Large Language Models Can Think While Reading},
publisher = {arXiv},
year = {2025}
}
For questions about the project, please contact jl-tong@sjtu.edu.cn or xyshen@eitech.edu.cn.